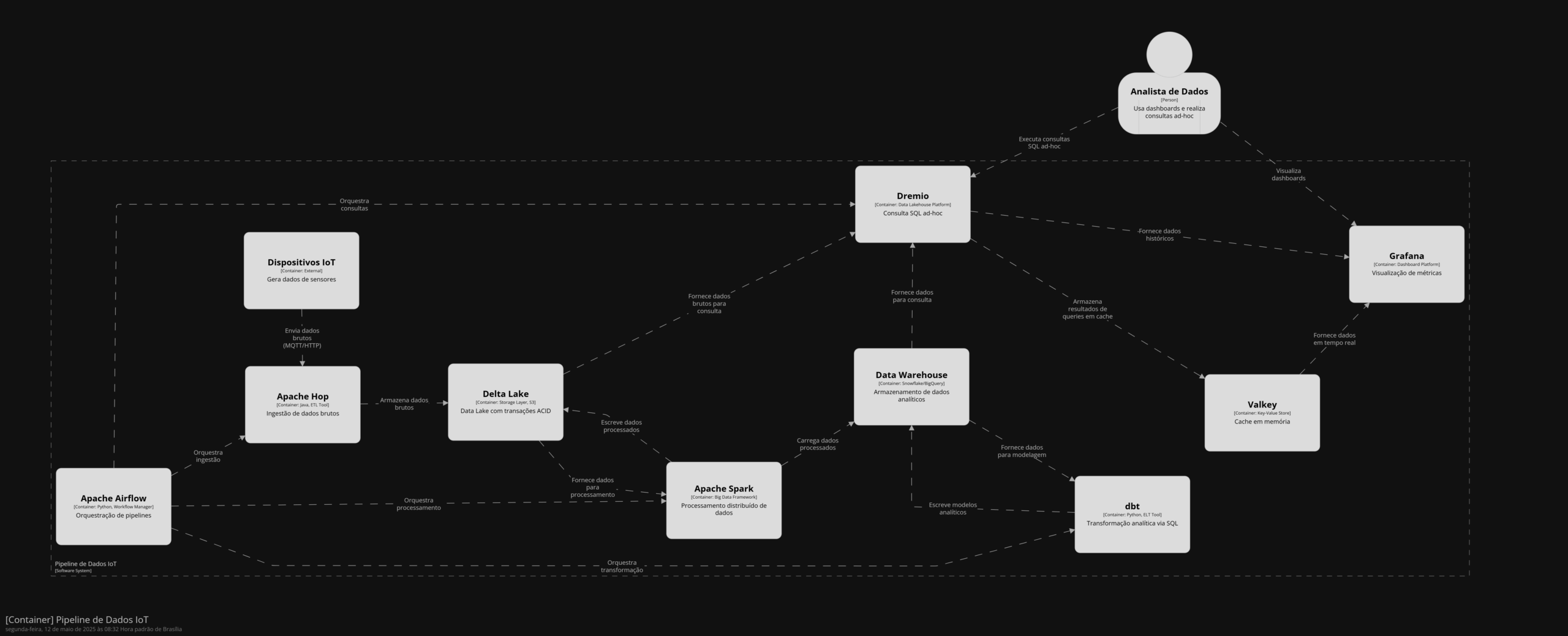
Apache Gobblin é uma plataforma de integração de dados open-source, projetada para simplificar a ingestão, extração, transformação e movimentação de dados de maneira escalável e eficiente. Inicialmente desenvolvido pelo LinkedIn, Gobblin tem como foco principal lidar com grandes volumes de dados distribuídos provenientes de diversas fontes e armazená-los em diferentes destinos, facilitando o gerenciamento e automação de pipelines de dados.
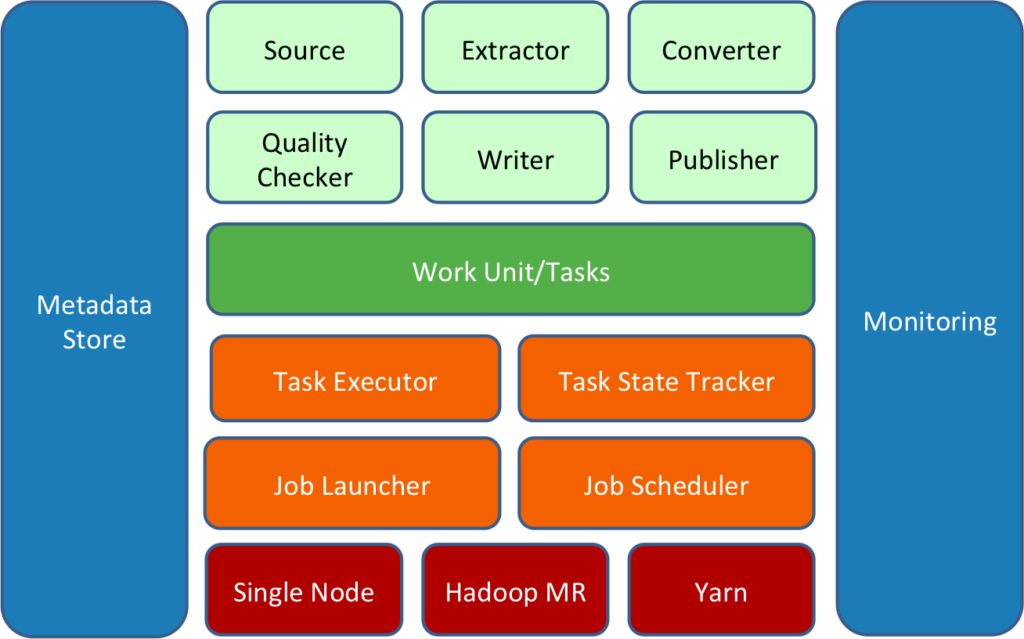
Principais características do Apache Gobblin:
Ingestão de dados escalável e distribuída
Gobblin facilita o processo de ingestão de dados em grande escala, extraindo informações de uma variedade de fontes e distribuindo-as em destinos como data lakes, data warehouses ou sistemas de armazenamento em nuvem.
Suporte a múltiplas fontes e destinos
Ele oferece integração nativa com diversas fontes de dados, como bancos de dados relacionais, sistemas NoSQL, Apache Kafka, Amazon S3, HDFS, e outros. Do lado de destinos, Gobblin suporta uma ampla gama de opções, como HDFS, Hive, Kafka, e S3.
Processamento de dados em lote e em tempo real
Gobblin é projetado para lidar com fluxos de dados em diferentes modos, permitindo tanto o processamento de dados em batch quanto o processamento de dados em tempo real ou near-real-time.
Transformação e limpeza de dados
Ele oferece funcionalidades para realizar transformações e limpezas nos dados à medida que são movidos de uma fonte para um destino, permitindo que os dados sejam preparados para análises ou outras aplicações.
Automação e orquestração de pipelines
Gobblin permite a criação de pipelines automatizados e gerenciáveis, que podem ser facilmente monitorados e escalados conforme necessário. Suas funcionalidades de agendamento permitem a execução periódica de pipelines de dados.
Alta disponibilidade e tolerância a falhas
A plataforma é desenhada para ser robusta, com suporte a recuperação automática de falhas e mecanismos de tolerância a erros, garantindo a confiabilidade no processamento de dados.
Arquitetura modular e extensível
Gobblin é altamente modular, facilitando a customização e extensão para atender a requisitos específicos, como adicionar novos conectores para fontes e destinos ou criar transformações personalizadas.
Monitoramento e gestão de dados
Ele oferece ferramentas para monitorar a execução dos pipelines, com relatórios detalhados sobre o estado das execuções e alertas em caso de falhas. Isso facilita o gerenciamento e a otimização dos processos de ingestão de dados.
Integração com sistemas de Big Data
Gobblin é integrado com diversas plataformas de Big Data, como Apache Hadoop, Hive, e Kafka, o que o torna ideal para cenários onde grandes volumes de dados precisam ser processados e gerenciados de forma distribuída.
Casos de uso do Apache Gobblin:
- Ingestão de dados para data lakes e data warehouses: Gobblin é amplamente utilizado para mover e processar dados de várias fontes para data lakes ou warehouses, facilitando a consolidação de dados para análise.
- Pipelines de dados em tempo real: Empresas podem usá-lo para configurar pipelines que processam fluxos contínuos de dados em tempo real, como logs, métricas e eventos.
- Transformação e preparação de dados: Ideal para empresas que precisam aplicar regras de limpeza, transformação e formatação nos dados antes de armazená-los ou utilizá-los para análises.
- Sistemas de integração de dados entre serviços distribuídos: Gobblin pode ser usado para movimentar dados entre diferentes sistemas distribuídos, como bases de dados relacionais, NoSQL, e sistemas de mensageria.
O Apache Gobblin é uma plataforma robusta e versátil para integração de dados em grande escala, ideal para empresas que precisam processar, transformar e mover grandes volumes de dados de forma automatizada e escalável.