O Apache Spark é uma das ferramentas open source mais populares e poderosas para processamento de grandes volumes de dados. Desenvolvido para ser rápido, escalável e fácil de usar, o Spark é um motor de análise unificado que suporta processamento em lote, streaming em tempo real, aprendizado de máquina, consultas SQL e análise de gráficos. Ele é amplamente utilizado em indústrias como tecnologia, finanças, saúde e telecomunicações, consolidando-se como uma solução versátil e eficiente no ecossistema de big data.
Originalmente criado no laboratório AMPLab da UC Berkeley, o Spark evoluiu para se tornar um projeto de destaque da Apache Software Foundation, com uma ampla base de usuários e uma comunidade ativa de desenvolvedores.
Principais Características
- Velocidade e Eficiência: O Spark utiliza a memória do cluster de forma inteligente, garantindo processamento rápido com mecanismos de otimização como DAG (Directed Acyclic Graph) para execução de tarefas.
- Processamento Unificado: Ele suporta múltiplos paradigmas de processamento:
- Batch Processing: Ideal para trabalhos ETL e transformações de dados.
- Streaming em Tempo Real: Através do Structured Streaming, permite lidar com fluxos de dados contínuos.
- Consultas SQL: Suporte a SQL ANSI com Spark SQL, facilitando análises ad hoc.
- Machine Learning: Biblioteca MLlib integrada para aprendizado de máquina escalável.
- Graph Processing: GraphX para análise de dados em formato de grafos.
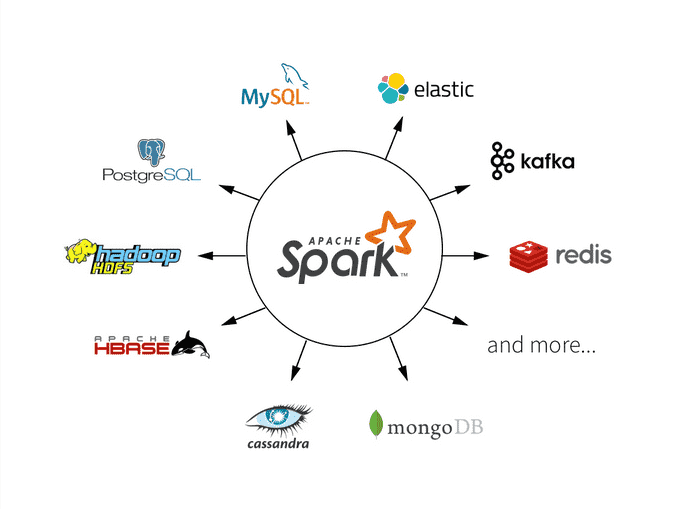
- Integração Robusta: O Spark conecta-se nativamente a diversas fontes de dados, como HDFS, Amazon S3, Apache Hive, Cassandra, MongoDB, e até bancos de dados tradicionais.
- Suporte a Múltiplas Linguagens: Oferece APIs em Scala, Java, Python e R, atendendo a uma ampla gama de desenvolvedores.
- Escalabilidade e Resiliência: Projetado para rodar em clusters distribuídos, ele escala horizontalmente e se integra perfeitamente a gerenciadores como Hadoop YARN, Kubernetes, e Apache Mesos.
Casos de Uso
- ETL em Larga Escala: Empresas utilizam o Spark para processar e transformar grandes volumes de dados antes de carregá-los em data lakes ou warehouses.
- Análise de Dados em Tempo Real: Com o Structured Streaming, permite análises contínuas de dados, como detecção de fraudes em transações financeiras.
- Machine Learning e IA: Usado para treinar modelos de aprendizado de máquina em grandes conjuntos de dados, especialmente em áreas como recomendações, previsões e detecção de anomalias.
- Análise de Grafos: GraphX é aplicado em cenários como análise de redes sociais e otimização de redes de transporte.
- Consultas Analíticas Avançadas: Spark SQL permite análises complexas diretamente em grandes volumes de dados, como logs de aplicativos e dados de sensores IoT.
Vantagens
- Alta Performance: Graças ao processamento na memória, é muito mais rápido que ferramentas tradicionais baseadas em disco, como Hadoop MapReduce.
- Flexibilidade: Um motor unificado que suporta diferentes tipos de cargas de trabalho.
- Open Source: Oferece liberdade para customização e integrações.
- Escalabilidade: Fácil de escalar para clusters gigantescos.
- Ecossistema Rico: Integra-se com quase todas as ferramentas de big data populares.
Desvantagens
- Consumo de Recursos: Pode exigir uma grande quantidade de memória e CPU para atingir seu potencial máximo.
- Curva de Aprendizado: Para novos usuários, a complexidade inicial pode ser intimidadora.
- Gerenciamento de Cluster: Configurar e gerenciar um cluster Spark pode ser desafiador sem experiência.
Como Começar
- Instalação Local: Baixe o Apache Spark no site oficial Apache Spark. Configure-o para rodar em modo local como ponto de partida.
- Configuração de Cluster: Integre o Spark a um gerenciador de cluster, como Hadoop YARN ou Kubernetes, para aproveitar o processamento distribuído.
- Primeiros Passos com Spark Shell: Experimente o Spark Shell (disponível em Scala ou Python) para explorar funcionalidades básicas.
- Primeiro Projeto: Crie um job simples de processamento de dados em Python ou Scala, como uma transformação básica em um conjunto de dados CSV.
- Integrações Avançadas: Experimente conectá-lo a fontes de dados como HDFS ou Amazon S3 e explore bibliotecas adicionais como MLlib para aprendizado de máquina.
O Apache Spark é mais do que uma ferramenta de processamento de dados; é uma plataforma que transforma a maneira como as empresas analisam e utilizam big data. Sua flexibilidade, velocidade e compatibilidade com o ecossistema moderno o tornam indispensável para aplicações analíticas e de processamento em larga escala.