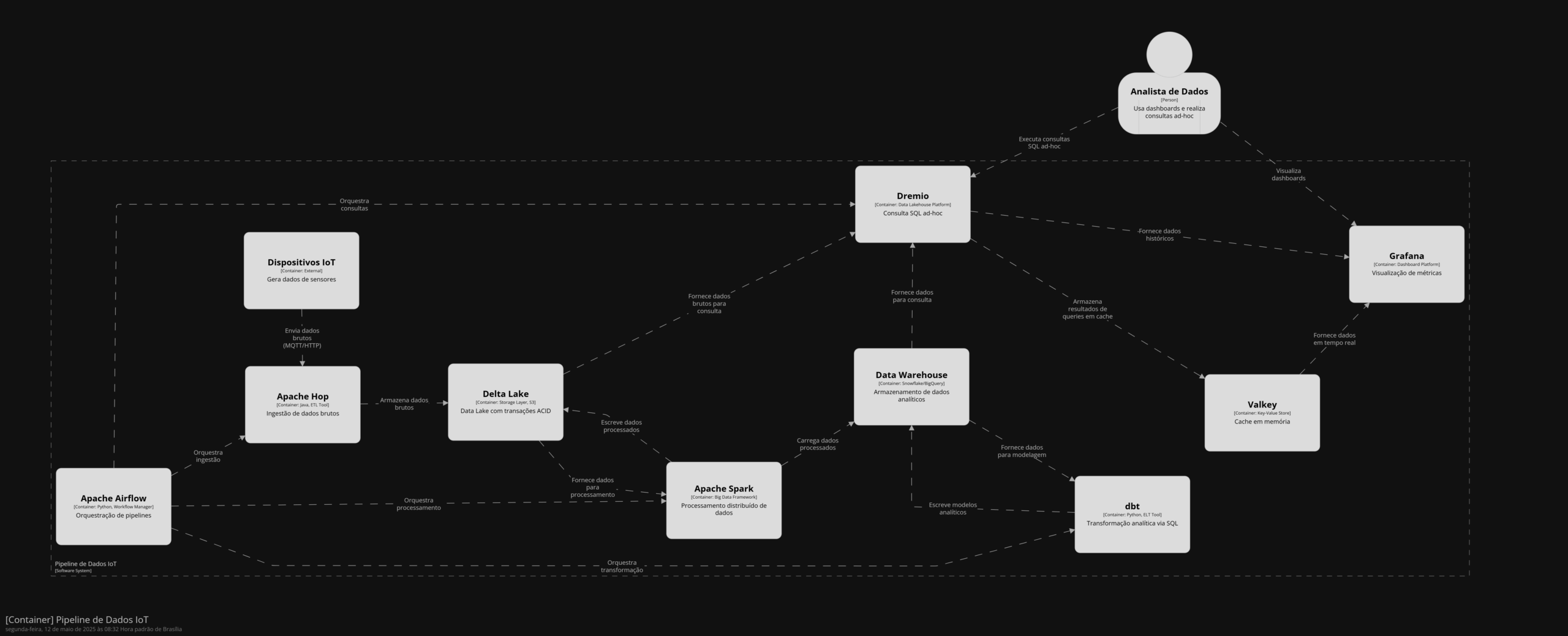
A engenharia de dados moderna exige ferramentas que sejam escaláveis, flexíveis e econômicas. O ecossistema open source oferece uma vasta gama de soluções que cobrem todas as etapas de um pipeline de dados: ingestão, transformação, armazenamento, orquestração, consulta, visualização e gerenciamento. Este artigo explora 23 ferramentas open source: Airbyte, Apache Hop, Meltano, Dremio, Presto/Trino, Apache Drill, Apache Pinot, Spark, Flink, Parquet, Avro, Delta Lake, Iceberg, Hudi, dbt, Airflow, Dagster, Dataform, Datafold, Grafana, CrateDB, Alluxio e Valkey, destacando suas funcionalidades, casos de uso, vantagens e como elas se integram para criar pipelines de dados robustos.
Ingestão de Dados
A ingestão de dados é o processo de coletar dados de fontes diversas (APIs, bancos de dados, streams) e entregá-los a sistemas downstream, como data lakes ou warehouses.
Airbyte
Plataforma open source para integração de dados, focada em conectar fontes a destinos com conectores pré-construídos.
Funcionalidades -> Suporta mais de 100 conectores, sincronização incremental, e criação de conectores personalizados via UI ou código.
Casos de Uso -> Extração de dados de APIs (ex: HubSpot, Shopify) ou bancos relacionais para BigQuery ou S3.
Vantagens -> Fácil configuração, comunidade ativa, e suporte a arquiteturas híbridas (nuvem e on-premise).
Limitações: Alguns conectores estão em fase beta, com funcionalidades limitadas.
Apache Hop
Ferramenta de integração de dados visual, derivada do Pentaho Data Integration (Kettle), projetada para criar pipelines de dados complexos.
Funcionalidades -> Interface gráfica para construir fluxos de ETL/ELT, suporte a batch e streaming, e integração com ferramentas como Spark e Kafka.
Casos de Uso -> Integração de dados em ambientes heterogêneos, como migração de dados entre sistemas legados e data lakes.
Vantagens -> Interface intuitiva, ideal para equipes com menos experiência em programação.
Limitações -> Menos flexível que ferramentas baseadas em código, como Airbyte, para pipelines altamente personalizados.
Meltano
Plataforma open source de ELT (Extract, Load, Transform) que combina ingestão, orquestração e transformação em uma CLI (Command Line Interface).
Funcionalidades -> Integração com Singer (padrão open source para conectores), suporte a dbt para transformações, e orquestração via Airflow ou Dagster.
Casos de Uso -> Pipelines ELT para equipes que preferem fluxos baseados em código, como sincronização de dados de CRMs para Snowflake.
Vantagens -> Altamente extensível, integração nativa com dbt, e abordagem DevOps-friendly.
Limitações -> Requer familiaridade com CLI e configuração manual de conectores Singer.
Consulta e Processamento Distribuído
Ferramentas de consulta e processamento distribuído permitem análises rápidas em grandes volumes de dados, seja em data lakes, warehouses ou bancos de dados.
Dremio
Plataforma de data lakehouse que unifica consultas SQL em data lakes, warehouses e bancos de dados, com aceleração via reflections (cache otimizado).
Funcionalidades -> Suporte a SQL padrão, integração com Parquet, Iceberg e Delta Lake, e visualização de dados integrada.
Casos de Uso -> Análise de dados em data lakes (S3, ADLS) sem necessidade de mover dados para um warehouse.
Vantagens -> Alto desempenho, suporte a formatos modernos, e facilidade para analistas SQL.
Limitações -> Configuração complexa em clusters grandes; algumas funcionalidades avançadas requerem a versão enterprise.
Presto/Trino
Presto (agora Trino) é um motor de consulta SQL distribuído, projetado para análises ad-hoc em grandes datasets.
Funcionalidades -> Suporte a múltiplas fontes (Hadoop, S3, MySQL), consultas federadas, e alta escalabilidade.
Casos de Uso -> Consultas exploratórias em data lakes ou integração de dados de fontes heterogêneas.
Vantagens -> Rápido para queries analíticas, suporte a conectores variados.
Limitações -> Não é otimizado para cargas de trabalho transacionais ou joins complexos.
Apache Drill
Motor de consulta SQL que permite consultas em dados estruturados e semiestruturados sem necessidade de schemas rígidos.
Funcionalidades -> Suporte a formatos como Parquet, Avro, JSON, e integração com HDFS, S3 e MongoDB.
Casos de Uso -> Análise exploratória de dados brutos em data lakes ou integração com sistemas NoSQL.
Vantagens -> Flexibilidade para dados semiestruturados, abordagem schema-on-read.
Limitações -> Menos maduro que Trino, com comunidade menor.
Apache Pinot
Banco de dados analítico em tempo real, otimizado para baixa latência e alta taxa de queries.
Funcionalidades -> Suporte a dados em streaming (Kafka), consultas OLAP, e escalabilidade horizontal.
Casos de Uso -> Dashboards em tempo real, como monitoramento de métricas de usuários em aplicações web.
Vantagens -> Excelente para cenários de baixa latência, integração com Kafka.
Limitações -> Configuração complexa e menos adequado para análises ad-hoc complexas.
Processamento de Dados
Ferramentas de processamento lidam com transformações em grande escala, tanto em batch quanto em streaming.
Apache Spark
Framework de computação distribuída para processamento de dados em larga escala, com suporte a batch e streaming.
Funcionalidades -> APIs em Python (PySpark), Scala, SQL, integração com Delta Lake, Iceberg, e bibliotecas para ML (MLlib).
Casos de Uso -> ETL em data lakes, treinamento de modelos de machine learning, ou processamento de logs.
Vantagens -> Escalabilidade, suporte a múltiplos formatos, e ecossistema maduro.
Limitações -> Alta complexidade em otimização de clusters; maior consumo de recursos.
Apache Flink
Framework de processamento de dados em streaming, com suporte a batch e baixa latência.
Funcionalidades -> Processamento baseado em eventos, exactly-once semantics, integração com Kafka e HDFS.
Casos de Uso -> Análise de dados em tempo real, como detecção de fraudes ou monitoramento IoT.
Vantagens -> Excelente para streaming, estado consistente, e alta taxa de throughput.
Limitações -> Curva de aprendizado mais íngreme que Spark para streaming.
Formatos de Armazenamento
Formatos de armazenamento otimizam a eficiência, compressão e acesso a dados em data lakes.
Parquet
Formato de armazenamento colunar otimizado para big data, amplamente usado em data lakes.
Funcionalidades -> Compressão eficiente, suporte a queries colunares, integração com Spark, Trino, e Dremio.
Casos de Uso -> Armazenamento de dados analíticos em S3 ou HDFS para consultas rápidas.
Vantagens -> Alta performance em queries analíticas, amplo suporte no ecossistema.
Limitações -> Não suporta transações ou atualizações incrementais nativamente.
Avro
Formato de dados baseado em linhas, ideal para serialização e streaming.
Funcionalidades -> Schema evolution, compactação, integração com Kafka e Hadoop.
Casos de Uso -> Ingestão de dados em streaming ou integração com sistemas que requerem schemas dinâmicos.
Vantagens -> Flexibilidade para mudanças de schema, tamanho compacto.
Limitações -> Menos eficiente para queries analíticas que Parquet.
Camadas de Armazenamento
Camadas de armazenamento adicionam governança, transações e escalabilidade a data lakes.
Delta Lake
Camada de armazenamento open source que adiciona transações ACID e governança a data lakes.
Funcionalidades -> Suporte a streaming/batch, versionamento, e integração com Spark.
Casos de Uso -> Data lakes com requisitos de auditoria ou operações de upsert/delete.
Vantagens -> Consistência, integração nativa com Spark, e suporte a ML.
Limitações -> Dependência do Spark para algumas funcionalidades.
Apache Iceberg
Formato de tabela para data lakes, com suporte a transações ACID e queries analíticas.
Funcionalidades -> Particionamento avançado, time travel, integração com Spark, Trino, Flink.
Casos de Uso -> Data lakes escaláveis com necessidade de evoluções de schema.
Vantagens -> Flexibilidade, suporte a grandes datasets, e integração ampla.
Limitações -> Menos maduro que Delta Lake em alguns casos.
Apache Hudi
Formato de tabela para data lakes, focado em atualizações incrementais e streaming.
Funcionalidades -> Suporte a upserts, integração com Spark e Flink, e gerenciamento de dados em tempo real.
Casos de Uso -> Pipelines que requerem atualizações frequentes, como tabelas de eventos em tempo real.
Vantagens -> Excelente para streaming e dados mutáveis.
Limitações -> Configuração complexa e menor adoção que Delta Lake ou Iceberg.
Transformação
Ferramentas de transformação modelam e preparam dados para análises ou aplicações.
dbt (Data Build Tool)
Ferramenta para transformações baseadas em SQL em data warehouses.
Funcionalidades -> Modelagem via SQL, testes de dados, gerenciamento de dependências.
Casos de Uso -> Criação de camadas analíticas em Snowflake ou BigQuery.
Vantagens -> Simplicidade para analistas, versionamento, e integração com orquestradores.
Limitações -> Limitado a SQL, menos flexível para transformações complexas.
Dataform
Plataforma de transformação de dados baseada em SQL, semelhante ao dbt, com foco em colaboração e versionamento.
Funcionalidades -> Modelagem em SQL ou JavaScript, integração com BigQuery, e interface web para gerenciamento.
Casos de Uso -> Pipelines analíticos em equipes que usam Google Cloud.
Vantagens -> Interface amigável, integração nativa com BigQuery.
Limitações -> Menos flexível que dbt para outros warehouses; comunidade menor.
Datafold
Ferramenta de validação de dados que automatiza testes de qualidade em pipelines.
Funcionalidades -> Comparação de datasets, validação de mudanças em pipelines, e integração com dbt.
Casos de Uso -> Garantir consistência de dados após alterações em pipelines ELT.
Vantagens -> Automatiza validação, reduz erros humanos.
Limitações -> Foco específico em validação, não é uma ferramenta de transformação completa.
Orquestração
A orquestração gerencia a execução de pipelines, garantindo dependências e monitoramento.
Apache Airflow
Plataforma para orquestração de fluxos de trabalho via DAGs (Directed Acyclic Graphs).
Funcionalidades -> Agendamento, monitoramento via UI, integração com Spark, dbt, e Kubernetes.
Casos de Uso -> Automação de ETL, pipelines de ML, ou integração de sistemas.
Vantagens -> Flexibilidade, grande comunidade, extensibilidade.
Limitações -> Configuração complexa em escala.
Dagster
Framework de orquestração baseado em Python, com ênfase em testabilidade.
Funcionalidades -> Pipelines como código, testes unitários, integração com dbt e Spark.
Casos de Uso -> Pipelines com forte necessidade de reprodutibilidade.
Vantagens: Sintaxe clara, suporte a DevOps.
Limitações -> Menos maduro que Airflow.
Visualização e Monitoramento
Ferramentas de visualização transformam dados em insights acessíveis.
Grafana
Plataforma de visualização e monitoramento, amplamente usada para dashboards operacionais.
Funcionalidades -> Suporte a fontes como Prometheus, CrateDB, e SQL, criação de dashboards interativos.
Casos de Uso -> Monitoramento de infraestrutura, métricas de pipelines, ou KPIs operacionais.
Vantagens -> Altamente personalizável, suporte a múltiplas fontes.
Limitações -> Foco em monitoramento, menos adequado para BI complexo.
Banco de Dados e Cache
Bancos de dados analíticos e sistemas de cache suportam acesso rápido a dados.
CrateDB
Banco de dados distribuído SQL, otimizado para grandes volumes de dados e queries analíticas.
Funcionalidades -> Suporte a SQL padrão, integração com IoT e time-series, escalabilidade horizontal.
Casos de Uso ->Análise de dados de IoT, logs, ou séries temporais.
Vantagens -> Simplicidade de SQL, alta escalabilidade.
Limitações -> Menos maduro que bancos tradicionais como PostgreSQL.
Alluxio
Sistema de arquivos distribuído que atua como camada de cache entre armazenamento e processamento.
Funcionalidades -> Cache de dados em memória, integração com S3, HDFS, e Spark.
Casos de Uso -> Aceleração de acesso a dados em data lakes para jobs Spark ou Flink.
Vantagens -> Melhora performance, abstrai armazenamento.
Limitações -> Complexidade adicional na configuração.
Valkey
Fork open source do Redis, um banco de dados em memória para cache e armazenamento de chave-valor.
Funcionalidades -> Alta performance, suporte a estruturas como listas e sets, integração com pipelines de dados.
Casos de Uso -> Cache de resultados de queries, armazenamento temporário em pipelines de streaming.
Vantagens -> Velocidade, simplicidade, comunidade crescente.
Limitações -> Ainda em transição do Redis, com ecossistema em desenvolvimento.
Por que Open Source?
Custo Zero -> Ideal para startups e equipes com orçamento limitado.
Personalização -> Código aberto permite adaptações específicas.
Comunidade -> Suporte global e atualizações frequentes.
Interoperabilidade -> Integração com nuvens públicas, sistemas legados, e ferramentas modernas.
E ai gostou do conteúdo? Então compartilha, conhecimento que não é compartilhado é inútil.