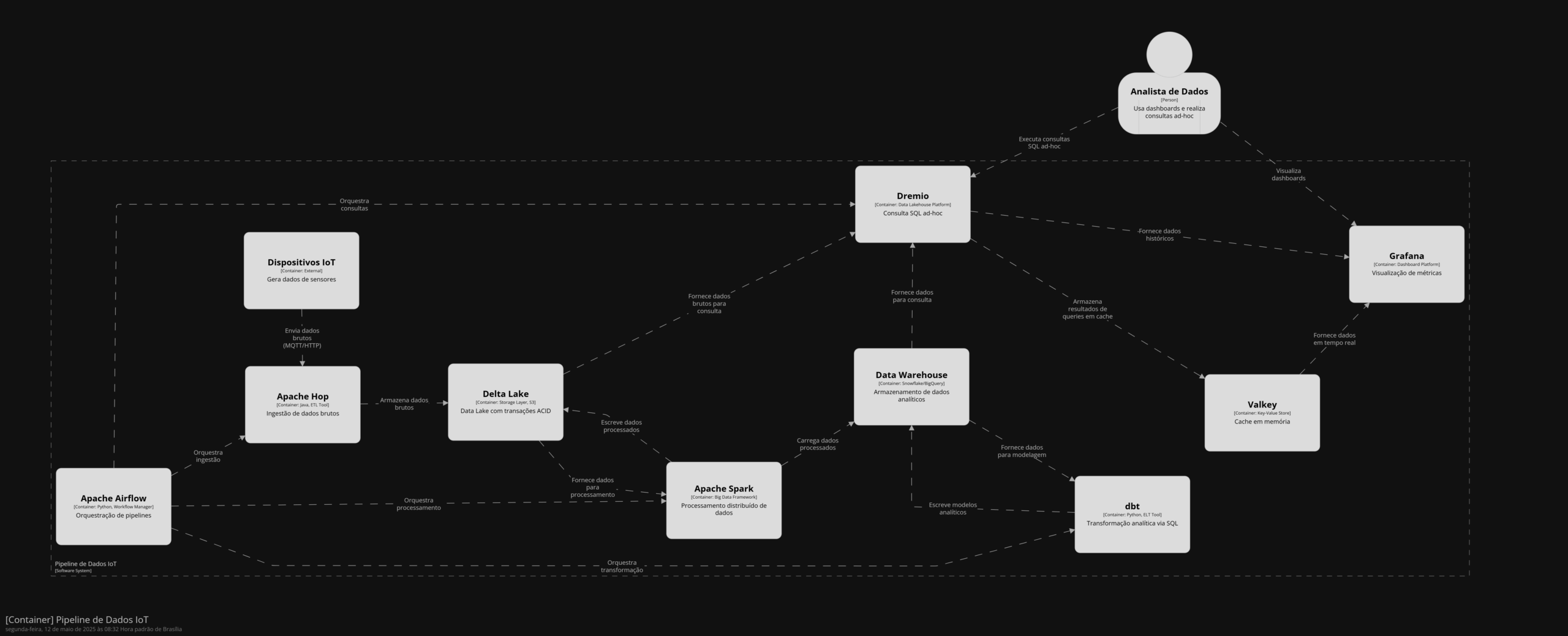
O Apache Flink é uma poderosa ferramenta open source para processamento de dados em tempo real e em lote. Projetado para oferecer alta performance, escalabilidade e flexibilidade, o Flink permite que desenvolvedores construam aplicações que processam grandes volumes de dados com baixa latência. Ele é particularmente reconhecido por sua arquitetura baseada em streaming de dados, o que o diferencia de frameworks tradicionais como o Apache Hadoop.
Principais Características
- Arquitetura Baseada em Streaming Nativo – O Flink foi projetado com o streaming em mente, garantindo que dados sejam processados em tempo real com consistência exatamente uma vez (exactly-once semantics). Esse é um grande diferencial em aplicações críticas como detecção de fraudes ou monitoramento em tempo real.
- Processamento Unificado de Dados – Além de streaming, o Flink também suporta processamento em lote, permitindo que desenvolvedores lidem com ambos os tipos de carga de trabalho em um único framework.
- Alto Desempenho e Escalabilidade – Graças ao uso de processamento paralelo distribuído, o Flink é capaz de escalar horizontalmente em clusters com milhares de nós, processando terabytes de dados em tempo real.
- APIs Flexíveis e Poderosas – O Flink oferece APIs em várias linguagens, como Java, Scala e Python, possibilitando o uso de diferentes níveis de abstração, desde APIs de baixo nível (Streams API) até APIs mais declarativas (Table API e SQL).
- Gerenciamento de Estado Robusto – Ele gerencia estados de aplicações de forma eficiente, oferecendo persistência e recuperação automática em caso de falhas, essencial para pipelines de dados contínuos.
Casos de Uso
- Monitoramento em Tempo Real – Empresas utilizam o Flink para analisar métricas operacionais e de negócio em tempo real.
- Detecção de Fraudes – Bancos e empresas financeiras monitoram transações em busca de comportamentos suspeitos.
- ETL Contínuo – Transformação e carregamento de dados para data lakes ou warehouses, substituindo processos tradicionais de ETL.
- Sistemas de Recomendação – Plataformas como e-commerce utilizam o Flink para gerar recomendações baseadas em interações do usuário ao vivo.
Vantagens
- Código aberto com uma comunidade vibrante e ativa.
- Suporte para diversas integrações, como Kafka, Cassandra, Elasticsearch, entre outros.
- Baixa latência para processamento em tempo real.
- Mecanismos avançados de tolerância a falhas.
Desvantagens
- Curva de aprendizado elevada para iniciantes em big data.
- Necessidade de um cluster robusto para lidar com grandes cargas de trabalho.
- Configuração e tuning podem ser complexos.
Como Começar
- Instalação – Baixe o Apache Flink no site oficial Apache Flink e siga a documentação para configurar um cluster local.
- Configuração de Ambiente – Utilize o Docker para criar um ambiente de desenvolvimento rápido e escalável.
- Primeiro Pipeline – Siga um tutorial básico da documentação oficial para criar um job de streaming simples.
- Integração – Experimente conectar o Flink com Kafka para ingerir dados em tempo real e Elasticsearch para armazenar os resultados.
O Apache Flink é uma escolha fantástica para empresas e desenvolvedores que buscam uma solução de ponta para processamento de dados em tempo real. Com sua arquitetura nativa de streaming, suporte a múltiplos paradigmas e desempenho incomparável, ele se destaca como uma das melhores ferramentas no ecossistema de big data open source. Ideal para projetos que demandam agilidade e precisão em grande escala, o Flink prova ser um investimento valioso em tecnologias open source.